





Machine learning and artificial intelligence have revolutionized multiple spheres and processes. As Paul Daugherty, Chief Technology and Innovation Officer at Accenture, says, “The playing field is poised to become a lot more competitive, and businesses that don’t deploy AI and data to help them innovate in everything they do will be at a disadvantage.” So the ML integration into pricing is not a modern whim but a necessity aimed at balancing and reasoning revenue and profit retailers yield.
In this regard, ML-driven product matching allows finding the suitable products and collecting data about them on different web stores and platforms. Later this data is used to plan and execute desired price positioning of a company in the market. With ML algorithms, product matching processes become automated, less time-consuming and even more accurate. In general, these factors make product matching an inevitable component of data delivery that is crucial in competition-based pricing.
Types of Product Matching
In highly competitive markets consumers judge a product's value based on competitors' prices for the same or equivalent goods. And big industry players apply competition-based pricing strategies to ensure their positioning, long-term competitiveness and price perception.
Competition-based pricing enables retailers to use smart pricing in order to stand out from other competitors, their assortment, promo and pricing strategies. For that reason, retailers may use product matchings on an ongoing basis to find equivalent products in other web stores and then process data about SKUs’ prices to decrease or increase them in line with the market.
There are different types of product matching retailers use across multiple industries:
-
Manual matching, as the name speaks for itself, means that specialists identify each matched pair on their own. They find identical products and check out whether they match. Although manual product matching has a higher accuracy rate, it is not really scalable and requires more time and human resources.
-
Barcode matching is a fully automated and never-stopping search of product URLs based on UPC, GTIN, or ASIN. However, the quality of these matches may sometimes be below the expectations due to verification complexity. Besides, a lack of data and limited search capacity are the main roadblocks to providing the full coverage of matched products.
-
ML-driven product matching is a fast and effective approach. It applies algorithms that speed processes up and cover a large volume of information, including various product features. Nevertheless, ML-driven product matching has its shortcomings. This approach requires proper data cleansing and high-quality datasets for ML model training.
Retailers may use one or a few approaches simultaneously, depending on the industry and their business needs.
How Product Matching Changes the Game
Product matching is a challenging process for businesses of all sizes because of the ever-growing wealth of assortment across stores and marketplaces that can be described on the site in different ways, whether mentioning a color, size, and other features or not. Therefore, retailers have to continuously update their dataset and keep it relevant.
The bigger the share of correctly matched products, the better data quality. The opposite can lead to numerous issues from incorrect new prices calculation to negative shopper experiences.
Complete and accurately matched data help retailers keep up their paces and get better results in the following processes:
-
data-driven assortment optimization
-
fast and effective decision making
-
product performance evaluation
-
enhanced consumer targeting
-
price and promo optimization

ML Matching in Detail
ML product matching is a complex process that requires incorporating images, titles, prices, and product characteristics into the model. In this article, we'll regard how product title matching functions.
The thing to know, ML title matching is a two-staged process based on two models. This pipeline allows for processing and optimizing data in a more effective way. The goal of the first model is to find potential pairs of products to match while the second model verifies a match. It's important to mention that only product titles are used so that it might be enough for accurate matching.
Model 1: Item Screening
The first model is lightweight. It serves for finding the most similar items from a client's store in a competitor’s store. To ensure good results, standardized unique identifiers in the product description are used. That's why before using the model, it is important to make a text preprocessing for product titles:
-
convert text to lower case;
-
remove extra spaces and characters, except for numbers, letters, periods, and hyphens.
Therefore, the first iteration, selection of the items for matching, is deployed with TF-IDF (Term Frequency — Inverse Document Frequency). However, if there’s a need for a more scalable tool, LSH (Local Sensitive Hashing) is better for this task.
Both models are based on 4-grams. These 4-character sequences of letters in a title are compared with titles on other web stores depending on how frequently they appear in the text.
For example, these are 4-grams for the word “samsung” : “sams”, “amsu”, “msun”, “sung”.
To evaluate the quality of selected candidates, the recall@k metric, with k=30 is used.

Selected candidates for each product are then used in a training dataset for further reranking by the second model.
Model 2: Items Ranking
After choosing potential candidates for matching, the second model helps define which pair of products will be a match or not. A multilingual neural network - XLM-RoBERTa allows receiving more stable results than other transformer-based models due to BPE tokenization. As an activation function, ELU with alpha=1.5 is used.
It’s crucial to use downsampling and setting custom class_weight during training in order to handle a somewhat unbalanced dataset in favor of the negative class (non-matches).
For a local validation of the second model, we are using a ROC-PR and F1 score, while on some steps also looking at precision and recall separately.


F1 score - a harmonic average between precision and recall
Precision - accuracy of matches
Recall - number of matches possible to find
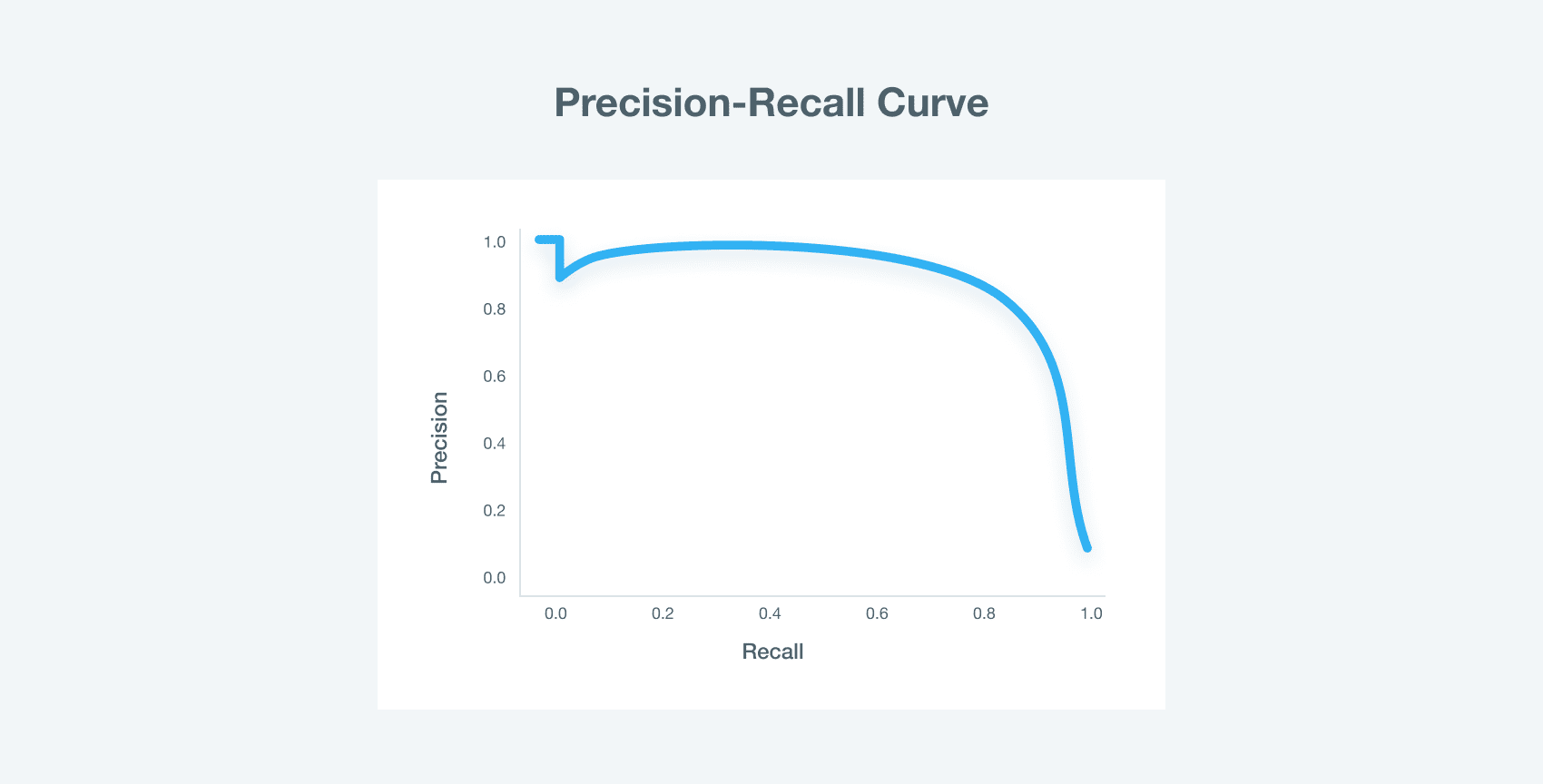

ROC-PR calculates precision and recall for each threshold for predictions. Then plots them on X and Y axes respectively
Hands-on Experience of ML Product Matching
To better understand how ML product matching functions across industries, let us have a look at the item ranking results obtained in DIY and electronics retail segments.
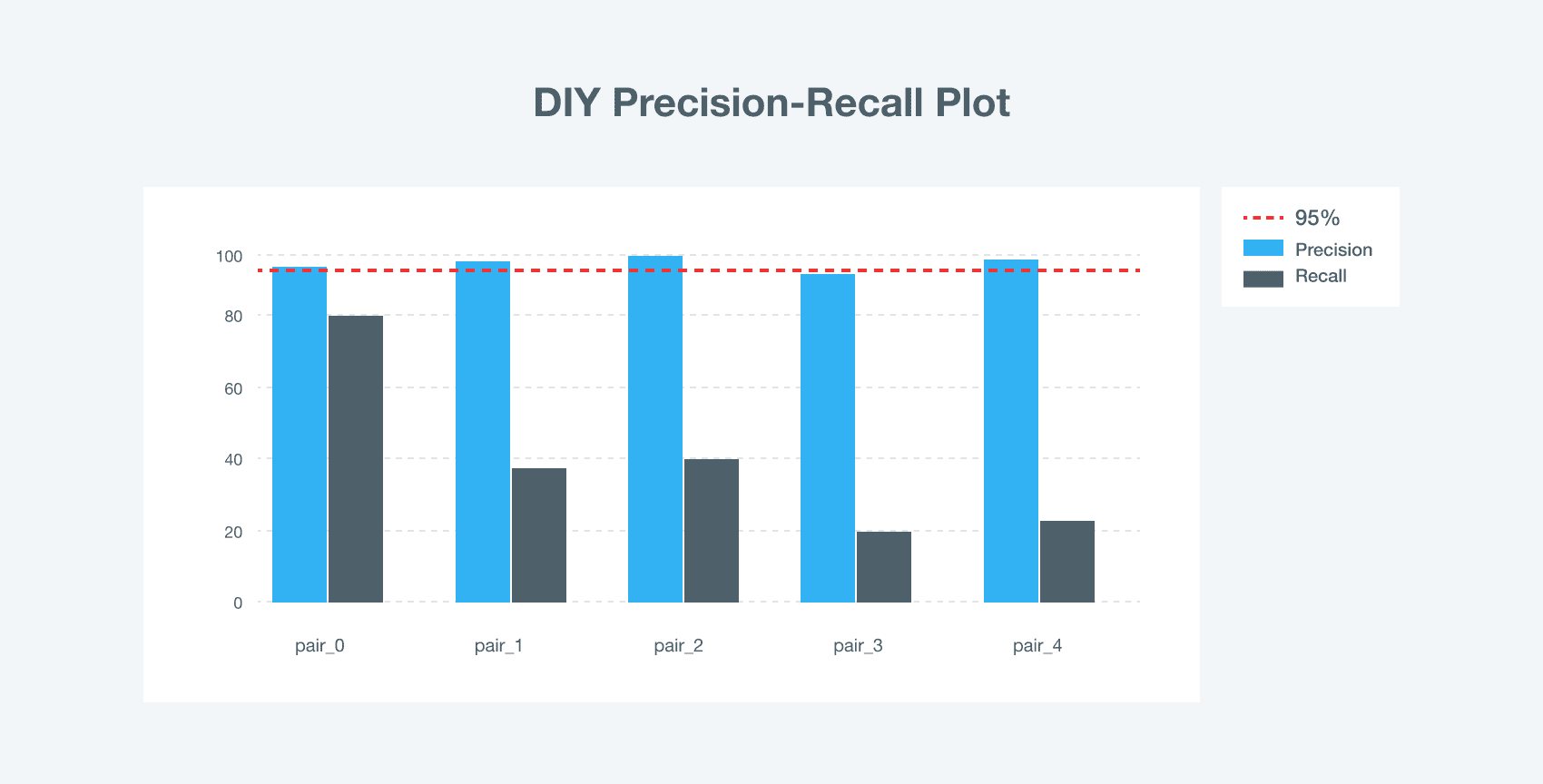


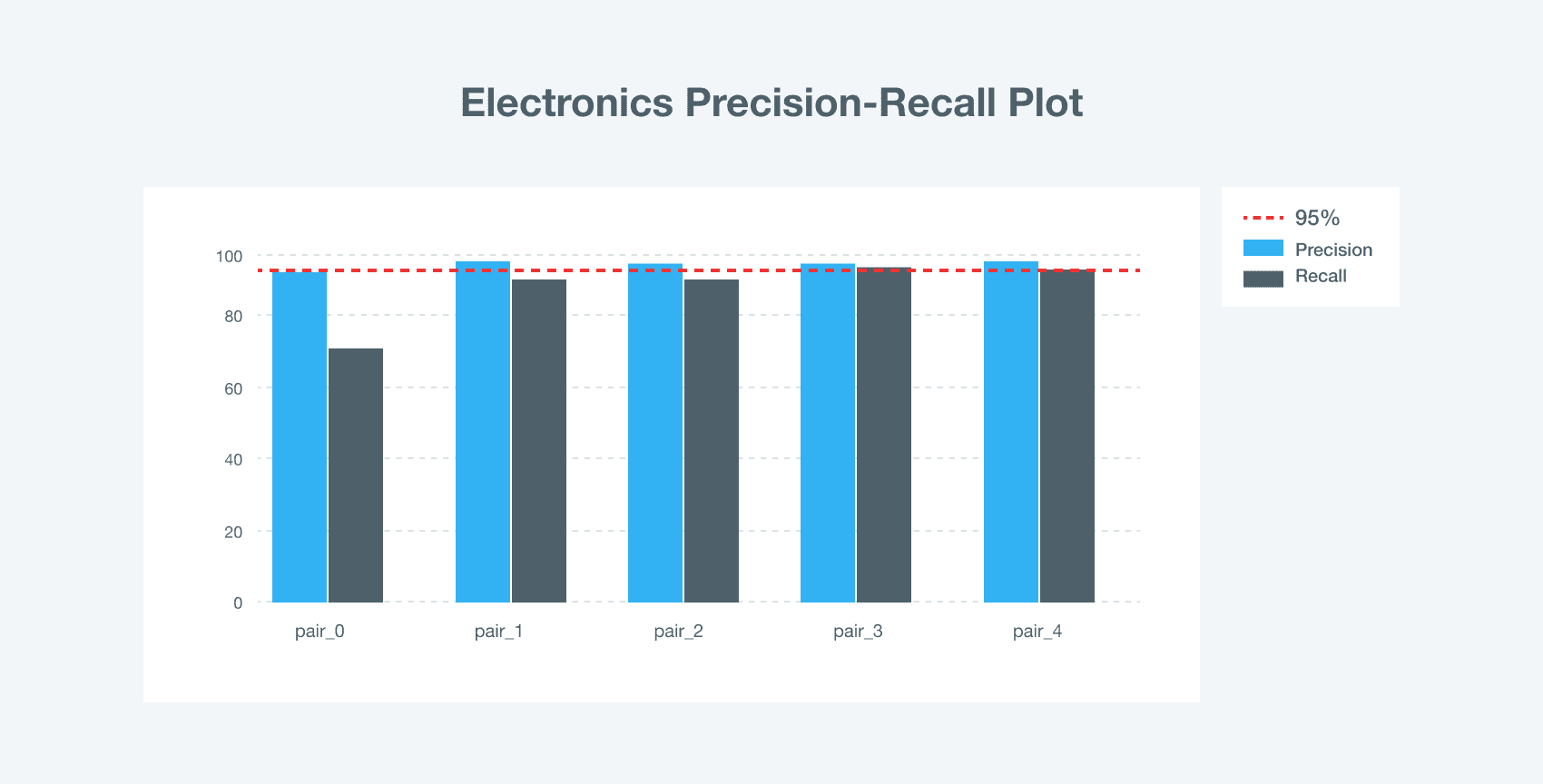
What we can see is the higher precision of product matching in electronics than in DIY. So the main challenge is the lack of structured information about goods in titles. A far more thorough description of electronic features with codes and identifiers, which DIY products oftentimes lack, fostered better results in title matching.
Key Takeaways
The need for accurate product matching is a challenge retailers can tackle using relevant data and ML to process it. Healthy competitive pricing data and a high-quality dataset are what every retailer needs to make the best use out of product matchings and maximize the value for the business. However, there’s no silver bullet. The best way to find a suitable product matching approach is to experiment with manual, code, and ML matchings to understand which specific combination of these approaches aligns best with your business needs and resources.
_______________________
The article is co-authored with Oleksii Tsepa, a Data Science specialist at Competera.







